Por EloInsights
• Empresas que queiram destravar seu potencial de transformação contínua (driven by change) precisam cultivar competências digitais fundacionais.
• Entre as capabilities que precisam ser refinadas e otimizadas está o processo de deployment de features e atualizações de produtos digitais.
• Essa competência, ainda que parte de um quadro maior, é chave para contribuir no processo de tornar a organização mais ágil e adaptável a um mundo de constantes disrupções.
Dentro de um contexto da transformação digital de uma organização, ou de adoção de uma postura Strategically Digital, que viabilize um uso estratégico de tecnologias habilitadoras como alavancas de negócio, um dos aspectos-chave é a capacidade de estabelecer uma cultura de transformação contínua. Para isso, as empresas devem criar fundações que viabilizem essa cultura orientada a mudanças. E entre as fundações, estão competências digitais que darão o suporte tecnológico necessário para todo esse processo.
Neste artigo, abordaremos um aspecto essencial do trabalho da TI de uma empresa, que se relaciona às competências digitais que precisam ser refinadas e otimizadas para garantir a saúde e capacidade transformacional de uma organização: o processo de deployment de features e atualizações de produtos digitais.
Mas, afinal, o que é um deployment (ou deploy)?
Trata-se de um processo em que os times de desenvolvimento, depois de já terem realizado os testes necessários em uma determinada feature ou aspecto de um software, seguem para disponibilizar a mesma em ambiente de desenvolvimento, QA (garantia de qualidade) e produção, ou seja, quando é disponibilizada para o usuário final.
Em outras palavras, o software segue para ambientes onde ele ainda não foi testado, e tradicionalmente, esse é o momento em que eventuais falhas e necessidades de correções aparecem.
“Por mais que sejam realizados inúmeros testes, quando chega a hora de disponibilizar a aplicação, é comum que surjam dificuldades até que tudo esteja rodando com confiabilidade para o usuário”, diz Rodrigo Bassani, CTO da EloGroup.
Por ser um aspecto tão crítico do processo de desenvolvimento e disponibilização de software, a forma como o deploy é realizado tem um impacto relevante na capacidade de uma organização de se manter ágil e de responder com velocidade às necessidades contínuas de transformação da mesma.
A seguir, vamos detalhar algumas das maneiras de se realizar um deployment de software, das mais tradicionais (e menos ágeis), até aquelas alinhadas com as práticas consideradas mais modernas e eficientes:
1 – Deployment manual
É um tipo mais antigo de deployment, muitas vezes associado a grandes dores na hora da implantação, e a uma estrutura on premise, ou seja, com servidores locais.
Consiste no envio do script com a atualização do software, um manual de instruções a ser executado por uma pessoa com acesso aos servidores, muitas vezes um terceiro que não participou do desenvolvimento do software em si.
“Nesse cenário o time de desenvolvedores entrava em call e esperava essa pessoa realizar o deployment”, diz Bassani. “Depois de seguir as instruções, ela devolvia para o time poder verificar se o processo tinha sido executado de forma adequada, ou se algo havia falhado.”
Um problema era o de escala, já que para ampliar essa operação eram necessárias mais pessoas na execução do script, o que aumentava a complexidade.
A falta de alinhamento e assimetria de conhecimento entre os times de desenvolvimento e a pessoa que executava o script tendia, neste modelo, a se traduzir em deployments longos e que muitas vezes não ocorriam de forma completamente satisfatória, independentemente do envio de um manual de instruções.
“Em caso de implantações mais críticas nesse modelo, não era raro ver demissões acontecerem durante o processo”, diz Bassani.
2 – Deployment parcialmente automatizado
Num segundo momento, o deployment passa a ser parcialmente automatizado, e começam a ser considerados aspectos de sua arquitetura.
O script não é mais rodado de forma manual por um terceiro; já se trabalha com versionamento do código (controle de versão do software em deploy) de forma mais estruturada, em repositórios que podem ser acessados pelos próprios desenvolvedores, e não mais por uma pessoa que não havia participado da criação daquele programa; existe todo um ambiente onde os “commits” (atualizações) ao código são submetidos, registrados e validados.
“Aqui, o processo de deployment começa a ser otimizado, e se torna menos doloroso para os times”, diz Bassani.
A informação pode estar disponibilizada tanto em ambiente on premise (data centers dentro das empresas) quanto em cloud (provedores de nuvem), em um contexto em que o código não precisa estar mais na máquina do desenvolvedor.
Esse tipo de deploy diminui a quantidade de erros humanos, pois não envolve mais um terceiro que não acompanhou o processo de desenvolvimento; a construção do código passa a ser administrada por quem realmente o conhece, por quem vai dar o suporte após a disponibilização do código, o que garante uma melhor visibilidade do estado de cada deploy.
Uma das vantagens dessa dinâmica: é possível fazer o “roll-back” (retorno à versão anterior) em caso de falha.
3 – Deployment completamente automatizado (CI/CD - Continuous Integration e Continuous Deployment)
Nesse contexto, os desenvolvedores passam a ter um controle completo do código, com ferramentas que auxiliam tanto na geração do build, no versionamento e disponibilização do software em produção; há um ganho considerável de eficiência, produtividade e de segurança no processo.
Há maior controle e maturidade no processo de deployment, que ganha uma visão de DevOps que envolve um ciclo contínuo de integração e implantação (Continuous Integration e Continuous Deployment).
“As sextas-feiras passam a ser tranquilas; deixa de ser necessário virar mais um final de semana inteiro realizando deployment. Antigamente, tínhamos ‘go-lives’ [momentos de viradas] de 36 horas ininterruptas no escritório; a gente cochilava, comia ali dentro até terminar o processo”, diz Bassani.
Na tabela a seguir, algumas das possíveis estratégias de deployment, suas respectivas vantagens e desvantagens:
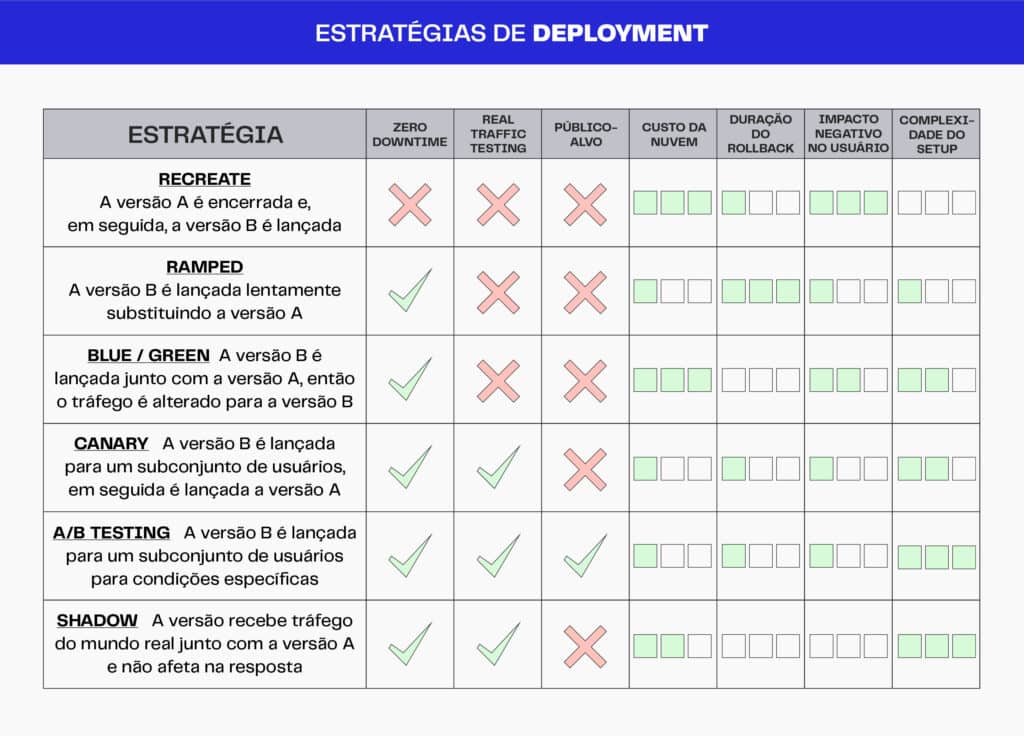
Uma das estratégias mais comuns é a de teste A/B, onde uma versão é disponibilizada para um conjunto específico de usuários, e seu comportamento é acompanhado pelo time de desenvolvimento.
Nesse contexto é definida a duração do roll-back em caso de falha, assim como o impacto para o usuário e a complexidade do setup do ambiente.
Num exemplo de um deployment realizado em diversas localidades, uma possibilidade seria disponibilizar o mesmo para uma primeira localidade, observar o seu comportamento em termos de experiência do usuário, e somente então seguir para o deployment nos outros locais, em caso de sucesso. “Hoje você tem, com a nuvem, uma facilidade nessa estratégia; o impacto é muito pequeno dentro das operações estruturadas em seu processo de deployment”, diz Bassani.

Um dos elementos que impactam diretamente na forma de se realizar um deployment é a arquitetura da aplicação em questão. Nesse aspecto, podemos falar sobre três principais gerações de arquitetura que predominaram no mercado, e sobre como eram os deploys dentro de cada um desses contextos:
Cliente servidor
- Deploy único
- Escala com hardware vertical
- Arquitetura Model-view-controller (MVC)
- Banco de dados único
- Releases mais complexos
Por volta do ano 2000, com a modernização das aplicações, predominou a chamada arquitetura cliente servidor. Nesse cenário, para o deployment, era necessário a instalação de um arquivo executável na máquina onde o mesmo seria realizado.
O único servidor era o do banco de dados, e as aplicações rodavam completamente nas estações de trabalho. Por isso, se uma organização tivesse 50 máquinas, por exemplo, os desenvolvedores tinham que gerar um pacote único de deploy e atualizar cada um dos computadores.
Sem um servidor exclusivo para a aplicação, era impossível escalar o processo de deployment de outra forma, o que aumentava a complexidade desse processo, que se tornava também mais custoso e demorado.
N layers
- Deploy independente
- Escala com hardware horizontal
- Arquitetura com “N” camadas
- Banco de dados único
- Release controlado
Na medida em que as tecnologias amadureceram, e recursos de infraestrutura se tornaram mais acessíveis, tornou-se predominante a arquitetura chamada N Camadas, ou N Layers, onde as aplicações podiam ser divididas em diferentes camadas lógicas e físicas. Ou seja, esse modelo já acomodava a existência de um servidor de aplicação, conectado tanto ao banco de dados quanto a um cliente mais leve, que trazia nas estações de trabalho apenas a tela da aplicação.
Isso se traduzia em uma vantagem importante: apesar de a aplicação ainda ser atualizada por inteira nesse paradigma, o deployment não precisava mais ser realizado em todas as máquinas que a rodavam localmente, e sim nos “n” servidores que atendiam ao total de estações de trabalho.
Se um único servidor atendia a 50 máquinas, por exemplo, era necessário atualizar a aplicação apenas nessa camada, e não mais nos 50 computadores. Nesse cenário, os deployments se tornaram mais controlados, mais baratos, e menos demorados.
Microsserviço / MicroFrontend
- Deploy em partes
- Escala por contexto funcional
- Arquitetura distribuída
- Múltiplos bancos de dados
- Release autônomos e escaláveis
O surgimento de fornecedores de serviços de computação em nuvem e a popularização dos mesmos marcaram uma virada na arquitetura de aplicações, e representam um marco nesse sentido.
A nuvem, que já existia em formato privado, tornou-se mais acessível em sua versão pública, em um contexto em que as empresas agora poderiam adquirir um “pedaço” de um data center cloud, minimizando custos e ampliando a flexibilidade.
Esse novo paradigma abriu as portas para um dos formatos mais discutidos no momento: a arquitetura baseada em microsserviços.
Nessa lógica, as aplicações deixam seu formato de “monolito” e passam a ser “desmembradas” em pedaços menores, diferentes contextos funcionais que passam a rodar em pacotes diferentes e independentes de deployment, o que permite atualizações mais focadas e precisas, que não impactam o todo da aplicação.
No caso de um software ERP (Enterprise Resource Planning), por exemplo, os diferentes módulos, como financeiro, de cadastro de clientes, vendas etc, passam a representar um pacote de deployment e um microsserviço separados e independentes. Ao realizar os deploys, eles ocorrem nos respectivos microsserviços, de acordo com cada alteração, o que se traduz em uma série de vantagens. Por exemplo, enquanto uma atualização ocorre em determinado microsserviço, os outros seguem inalterados e operantes, o que se traduz em ausência de “downtime” (serviço fora do ar) para os usuários.
Uma arquitetura baseada em microsserviços também viabiliza uma evolução nas ferramentas de controle de código fonte e de automação de deploys e release.
As diferenças de administração e configuração de setups on premise e cloud
A seguir, detalhamos algumas das principais diferenças entre a administração e configuração de setups tipo on premise (que rodam em servidores locais, operados pela própria organização) e cloud (servidores operados fora da organização, por fornecedores de infraestrutura sob demanda):
Características da administração e configuração de um setup on premise:
- É necessária a gestão do licenciamento dos softwares;
- Gestão de capacity planning da infraestrutura;
- Gestão física dos servidores e datacenters;
- Provisionamento de infraestrutura complexo;
- Deployment in-house;
- Complexidade para escalar aplicações;
- Aplicação de patches de SO de responsabilidade própria;
- Processo de deployment de “disaster recovery” mais complexo;
No ambiente on premise, uma das principais diferenças é a necessidade de a própria organização se responsabilizar pela gestão dos tipos de deployment de software, e pela governança do sistema operacional suportado naquele ambiente.
O deployment ocorre “dentro de casa”, então as equipes de TI precisam provisionar infraestrutura e ter o local físico para a mesma (“capacity planning”). Isso se traduz em maior complexidade na hora de escalar, em outras palavras, ampliar o tamanho dessa infraestrutura, o que ocorre por meio de investimentos no hardware, e não de forma flexível como em ambiente cloud.
A aplicação de patches e atualizações também é de responsabilidade da organização.
O processo de planejamento de “disaster recovery”, onde é determinado um plano de contingência em caso de disrupções graves dos data centers, como no cenário de um ciberataque bem-sucedido, é mais complexo, pois muitas vezes envolve o deslocamento físico das equipes de TI para outras localidades para realizar a configuração dos ambientes de backup.
Em suma, a configuração on premise tende a ser mais custosa, e hoje ainda representa a realidade para um grande número de empresas, na medida em que setups em nuvem começam agora a ganhar escala.
Características da administração e configuração de um setup cloud:
- Flexibilidade para escalar infraestrutura;
- Eficiência para disponibilização de novo produto;
- “Pay as you go”;
- Otimização dos processos de deployment;
- Maior facilidade de gestão;
- Alta disponibilidade;
- Agilidade para criação do processo de “disaster recovery”;
Num ambiente cloud, a organização consegue ter mais flexibilidade para escalar a infraestrutura de acordo com o aumento de suas necessidades, sem que seja preciso um investimento próprio em hardware. Nesse cenário, acaba também a necessidade de se ter, e gerenciar, um espaço físico para abrigar data centers.
Essa flexibilidade se traduz em mais eficiência na disponibilização de novos produtos e também na melhoria da gestão da infraestrutura. Na lógica “pay as you go”, se a organização precisar hospedar uma aplicação pequena, que ocupe um pequeno espaço de servidor, ela poderá contratar apenas a capacidade computacional correspondente.
No planejamento de disaster recovery, o ambiente cloud é mais configurável e possibilita a disponibilização de servidores sem a necessidade da presença física em diferentes localidades.
Pessoas em primeiro lugar
Ao comparar os dois tipos de ambiente, a conclusão é de que o on premise é mais complexo, exige a execução de mais etapas, além de um número maior de funcionários ou pessoas responsáveis pela infraestrutura. Ao optar por um fornecedor cloud, esse conjunto de times e serviços já vem encapsulado no contrato.
Mas vale lembrar que qualquer deployment nunca será apenas um clique de botão; este é um processo que demanda níveis de maturidade digital e que pode ser totalmente arcaico e feito de forma amadora, tanto em ambiente on premise quanto cloud.
No fundo, o que fará diferença é o time envolvido nessa operação; as pessoas e sua capacidade de conferir à organização uma maior maturidade em suas competências digitais.











