Por Lucas De Vivo, Raphael Sá, Rafael Cabral e Daniel Franzolin
- O desafio de Machine Learning surgiu devido à necessidade de reduzir a divergência encontrada pela re.green entre as análises manuais e automáticas das terras captadas.
- O modelo de ML atua no processo de captação e análise de terras e oferece maior precisão no momento de classificar áreas restauráveis, o que permite uma abordagem mais eficiente e assertiva na tomada de decisão sobre a aquisição das terras.
- Com a integração do modelo ao algoritmo já utilizado (AMORE), houve uma redução de 28,7% no erro de área restaurável e de 10,7% no erro do cálculo do NPV (valor presente líquido) potencial da terra.
Em nossa série de artigos sobre como um projeto full-stack ajudou a re.green, empresa brasileira focada na recuperação de biomas da Amazônia e Mata Atlântica por meio de um modelo de negócios inovador, a tornar sua operação mais eficiente, já abordamos alguns tópicos importantes. Primeiro, focamos na solução tecnológica completa que acelerou a captação de terras.
Depois, detalhamos o processo de monitoramento das mesmas e a arquitetura de dados que viabiliza esse processo. Agora, colocaremos atenção em outro elemento-chave de todo esse projeto. Neste insight, abordaremos técnicas de Machine Learning (ML), ou aprendizado de máquina, implementadas na primeira etapa dessa grande cadeia de negócio, a captação e análise de terras, para ajudar a diminuir divergências entre análises manuais e automáticas.
Entenda, a partir de agora, como a EloGroup construiu e implementou a estrutura de Machine Learning para auxiliar a re.green em seu desafio!
O que é Machine Learning e como ele se diferencia de outras automações
Machine Learning, ou aprendizado de máquina, é uma subárea da inteligência artificial que permite que sistemas “aprendam” padrões e façam previsões com base em dados, sem serem explicitamente programados para cada decisão. Diferente de outras formas de automação, como regras fixas ou scripts baseados em lógica determinística, o ML é capaz de lidar com complexidade, incerteza e variações nos dados.
Em uma automação tradicional, por exemplo, se define uma sequência de condições: “Se a imagem tiver tal cor, classifique como restaurável”. Já no Machine Learning, o modelo é treinado com diversos exemplos de imagens já classificadas e, com base nesses padrões, aprende a generalizar e tomar decisões mesmo diante de novos casos que nunca viu antes.
Essa capacidade de adaptação é especialmente poderosa em contextos como o da re.green, que lida com imagens de satélite de diferentes qualidades, condições climáticas, biomas e níveis de regeneração.
O ML permite que o sistema evolua continuamente conforme novos dados são incorporados, entregando análises mais precisas e contextualizadas. Isso representa uma mudança de paradigma: de decisões baseadas em regras fixas para decisões baseadas em aprendizado estatístico e evidência empírica.
Por que aplicar Machine Learning no contexto re.green
Como abordamos anteriormente, a natureza diversa dos dados trabalhados pela re.green torna sua operação uma boa candidata à implementação de técnicas de Machine Learning.
“Era necessário usar um modelo avançado que fizesse a classificação de áreas restauráveis usando imagens multiespectrais”, aponta Daniel Franzolin, especialista de dados e modelagem da re.green.
Inicialmente, o ML no contexto re.green foi aplicado à captação, detecção e classificação da área (para mais detalhes desse processo, leia o primeiro artigo dessa série).
Antes da introdução do ML, a análise das terras era feita de forma manual pelos técnicos, com ajuda de um algoritmo chamado AMORE.
AMORE é a sigla para Algoritmo de Alocação de Modelos de Restauração re.green. Ele utiliza camadas espaciais públicas, como Mapbiomas e SRTM, realizando a classificação espacial de cada pixel do perímetro da fazenda de acordo com o seu grau de restauração, regeneração natural e mecanização.
Esse processo é essencial para definir a alocação de modelos de restauração de forma automática. Entretanto, erros na alocação geram parâmetros financeiros que não representam a realidade e, consequentemente, trazem riscos econômicos à re.green.
Ao mesmo tempo, as fontes espaciais do AMORE consideram o espectro nacional, com uma resolução de 10x10m e uma frequência anual de atualização. Essas características dificultam a evolução e acurácia, exigindo a aplicação de técnicas e recursos mais avançados como, por exemplo, Machine Learning.
A aplicação de ML nesse contexto teve como foco inicial a otimização da classificação da área restaurável das fazendas, uma das três responsabilidades do algoritmo de alocação.
Como foi a implementação do algoritmo de Machine Learning
O modelo de Machine Learning tem o objetivo de categorizar, a partir das imagens obtidas por satélite, as partes da terra que têm potencial de restauração e as que não têm. Para isso, ele utiliza como insumo o polígono cadastral que representa o perímetro da propriedade.
Optou-se por utilizar um modelo de rede neural. Rafael Cabral, gerente técnico do projeto na EloGroup, explica a escolha: “Na literatura, são os mais indicados para a segmentação semântica de imagens de sensoriamento remoto. Os estudos mostram que mesmo em casos com poucos dados, as redes neurais performam melhor.”
Ao tratar modelos de redes neurais, um desafio inicial é definir uma arquitetura adequada para o desafio em questão. Nesse caso, foi usada a ResNet como encoder (parte inicial da rede, responsável por extrair características de alto nível dos dados).
O decoder, parte final da rede, responsável por processar as informações extraídas do encoder e chegar no mapa final de áreas classificadas, foi o DeepLabV3+, que divide imagens em partes para identificar e separar objetos com precisão. Essa escolha é feita com base em revisão bibliográfica e análise crítica das necessidades do modelo a ser desenvolvido.
Após a definição da arquitetura, foi necessário treinar o modelo para que ele aprendesse como capturar os padrões específicos de cada tipo de pixel.
1. Desenvolvimento e treino do ML
Para fazer o treino do novo modelo de ML foram selecionadas 128 terras, que possuíam polígonos de área restauráveis classificados manualmente e cujas imagens de satélite tinham a qualidade mínima exigida para executá-lo.
Devido ao baixo número de terras disponíveis para treino, validação e teste, foi preciso utilizar um método conhecido como sliding windows (janela deslizante), que envolve uma divisão maior dos dados em janelas de dimensão específica, com processamento individual.
Ao dividir as terras selecionadas em treino, validação e teste em uma proporção de 80%/10%/10%, pode-se então gerar os dados que de fato serão utilizados no processo de treinamento.
O conjunto de treino alimenta o algoritmo de aprendizado do modelo, enquanto o conjunto de validação é usado em cada iteração (época) para monitorar a performance do modelo em dados fora da amostra de treino, permitindo uma avaliação de qualidade geral do modelo e seleção de hiper-parâmetros, valores que definem como o processo de treino se dará. Um desses hiper-parâmetros é o número de épocas, que dita o momento de parada do aprendizado.
Finalmente, o conjunto de teste é utilizado para calcular as métricas de qualidade geral do modelo, trazendo uma visão de performance em dados nunca vistos.
Essa avaliação será importante para entender de forma profunda o comportamento do modelo em ambiente produtivo, tanto em métricas puramente técnicas, como precisão, recall e IOU (intersection over union), quanto em métricas que refletem a lógica de negócio, como a redução do trabalho de correção das áreas demarcadas.
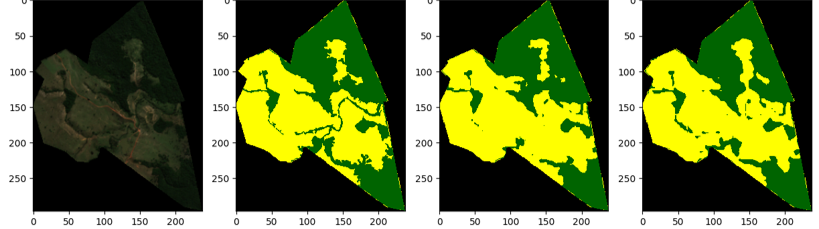
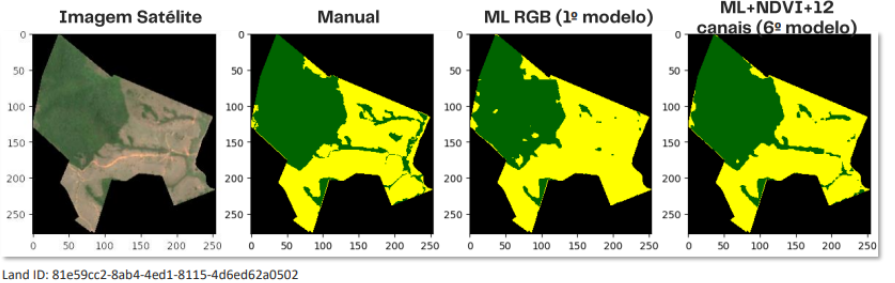
Nas imagens acima, é possível ver a comparação entre a imagem de satélite, a análise manual e dois momentos do treino no modelo de ML, sendo o último o mais recente.
2. Funcionamento do modelo
Ao receber as informações do satélite, o modelo de Machine Learning lê as fotos e inicia uma categorização da área representada em restaurável ou não restaurável. Isso é feito individualmente, a cada pixel (10x10m), e interpretando os pixels próximos para construir polígonos menores dentro do desenho maior.
Raphael Sá, gerente do projeto na EloGroup, explica que, para o modelo ser efetivo, era necessário garantir o uso de imagens mais recentes: “Para isso foi realizado o provisionamento de um mecanismo capaz de consumir imagens de satélite mais recentes para cada terra. Com essa obtenção feita a partir da API do satélite Sentinel-2 garantimos uma maior precisão frente ao AMORE, que utiliza camadas espaciais como Mapbiomas e SRTM com uma frequência anual de atualização.”, aponta.
Para fazer a classificação, o modelo utiliza alguns parâmetros de acordo com a imagem adquirida:
- Cor (RGB) apresentada na foto, que indica se há a presença de espécies;
- 12 canais de avaliação entregues pelo próprio satélite (bandas espectrais que permitem a captação de diferenças no estado da vegetação, umidade, rios, solos e áreas costeiras por meio de ondas eletromagnéticas);
- NDVI (Índice de Vegetação por Diferença Normalizada), uma variável de –1 a 1 entregue pelo Sentinel e calculada com base na reflexão espectral obtida pelas 12 bandas, que vai do vermelho visível ao infravermelho próximo. Em suma, mede o verde e a densidade da vegetação.
Com base nisso, o ML gera como output uma imagem verde e amarela, com o verde representando a área não restaurável (onde já existem espécies) e o amarelo a área restaurável. Esses dados servirão como um “mapa” para as próximas etapas.
Como o modelo de Machine Learning contribui para as próximas etapas do AMORE
Após a classificação de área restaurável pelo modelo de ML, as demais classificações de regeneração natural e mecanização consideram as mesmas premissas do AMORE.
Essa avaliação categoriza cada pixel da fazenda de acordo com os seguintes níveis:
1. Regeneração natural
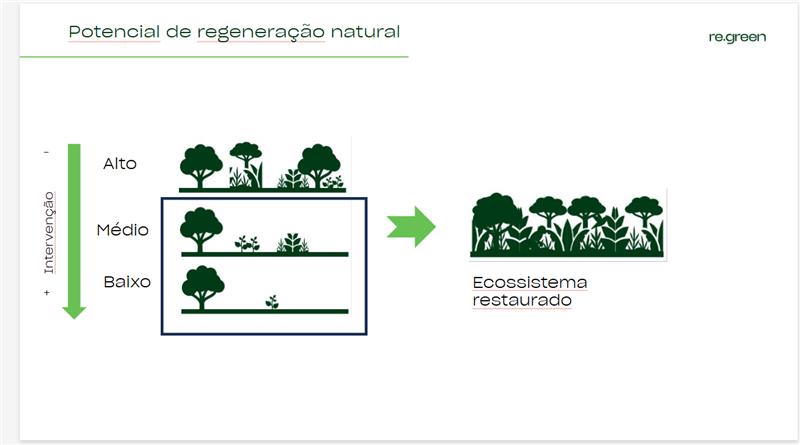
O potencial de regeneração natural da terra é verificado de acordo com a quantidade de espécies (árvores) presentes em cada pixel avaliado, classificando-os em baixo (BRN), médio (MRN) ou alto (ARN). Essa delimitação é feita pelo AMORE a partir de uma análise de proximidade de fragmento florestal do entorno de cada pixel.
Áreas com baixa incidência de indivíduos regenerantes (pasto limpo) são classificados como baixo potencial de regeneração. Nesses casos, apesar do maior volume gerado de créditos de carbono os custos de restauração acabam sendo mais elevados pela maior intensidade no manejo florestal.
2. Mecanização
Após a classificação do grau de regeneração natural, cada pixel é classificado de acordo com o nível de mecanização.
A presença de alta declividade ou alta presença de indivíduos regenerantes (ARN – pasto sujo) dificultam o uso de máquinas no manejo florestal e exigem aplicação de técnicas manuais ou drone.
Para realizar essa classificação é utilizada a camada espacial do SRTM sendo aplicados limites de declividade para cada região, possibilitando codificar as áreas da fazenda com Y (mecanizável) ou N (não mecanizável).
Machine Learning e o cálculo de valor da terra
Em um segundo momento, o modelo ML também influencia, ainda que indiretamente, no cálculo no cálculo dos parâmetros financeiros NPV (ou Valor Presente Líquido) e TIR (ou Taxa Interna de Retorno) das terras analisadas., essencial para a execução do processo de negociação e aquisição.
Além das condições comerciais de aquisição da fazenda e premissas financeiras bases – como curvas de geração de carbono e custos de restauração -, os resultados financeiros estão diretamente conectados à alocação de modelos de restauração definida para o perímetro analisado.
Em resumo, erros obtidos na classificação de área restaurável, regeneração natural ou mecanização implicam em resultados financeiros com uma margem de erro maior. Com a aplicação do modelo de Machine Learning foi possível aumentar a precisão na classificação de área restaurável, estendendo esses resultados ao cálculo financeiro da fazenda.
“Com uma maior precisão na alocação de área restaurável, aumentamos indiretamente a precisão do cálculo financeiro automático. Isso acaba destravando alternativas de automação no processo que ainda não foram colocadas em prática, como por exemplo, aprovação automática para negociação.”, explica Raphael.
A adoção de ML em parte do processo do AMORE reduziu em 28,7% o erro relativo de área restaurável e em 10,7% o erro relativo ao NPV do modelo automático.
Resultados
Para avaliar a eficiência da implementação do Machine Learning no processo de análise espacial foram selecionadas 60 terras. Os resultados do modelo de ML foram comparados com os resultados do AMORE e resultados manuais feitos por especialistas.
“Ao final, a solução apresentou melhoria em todos os indicadores e reduziu a variabilidade do resultado. Isso reforçou a tese de que, a longo prazo, se aumentarmos o volume de dados anotados de áreas restauráveis, podemos incrementar ainda mais o resultado com a execução de novos treinos do modelo.”, aponta Rafael Cabral.
Diante dessa amostragem houve uma redução da mediana do erro absoluto de 6.85% do AMORE vs análise manual para 2.6% no caso do ML vs análise manual. Isso significa que o modelo automático ML é 62% mais acurado nos resultados do que o modelo automático AMORE.
“Como resultado disponibilizamos uma estrutura capaz de executar o modelo de ML 100% integrada ao workflow (MLops) de captação de terras. Em resumo, toda terra que é prospectada e cadastrada na aplicação atualmente possui não só a execução dos modelos automáticos AMORE, mas também a execução automática do novo modelo de ML. Dessa forma, conseguimos acompanhar os resultados obtidos com as duas execuções automáticas ao longo de todo o funil de aquisição nas diferentes ferramentas de gestão utilizadas”, diz Sá.
Conclusão
A implementação do modelo de Machine Learning representa um avanço significativo no processo de captação e análise de terras para restauração. Com mais precisão na categorização das áreas, a tecnologia não só aprimora a eficiência do trabalho, mas garante uma abordagem fundamentada e assertiva na tomada de decisão relacionada à aquisição das terras.
“As abordagens tradicionais, como o algoritmo AMORE, apesar de úteis, apresentavam limitações significativas devido à resolução espacial e à frequência anual de atualização dos dados, o que gerava divergências entre as análises manuais e automáticas”, aponta Franzolin.
Integrando o aprendizado de máquina ao AMORE, o fluxo de trabalho se torna mais eficiente e há uma importante redução nos erros quando comparado ao que se via anteriormente. Isso, em médio e longo prazo, amplia as vantagens competitivas da re.green como um player no mercado de créditos de carbono e venda de madeira.
Daniel ainda aponta que a adoção de Machine Learning, especialmente redes neurais, permitiu lidar com a complexidade e variabilidade dos dados de satélite, aprendendo padrões sutis e adaptando-se a diferentes condições de terreno, biomas e qualidade de imagem. “Essa capacidade de generalização e melhoria contínua foi essencial para superar as limitações das regras fixas e alcançar uma classificação mais precisa e confiável das áreas restauráveis.”
Segundo Raphael Sá, a infraestrutura provisionada permite um avanço futuro ao time de tecnologia da re.green: “Com a arquitetura provisionada pavimentamos o caminho para que os experimentos com ML na análise automática continuem acontecendo. Além de viabilizar aplicação de novos treinos e testes no modelo atual – com foco na classificação de área restaurável –, é possível expandir a adoção para otimizar outros momentos da análise – como regeneração natural ou mecanização –, e até mesmo avaliar o uso de constelações de satélites que tragam uma maior resolução”, completa.
LUCAS DE VIVO é Redator de EloInsights
RAPHAEL SÁ é Gerente na EloGroup
RAFAEL CABRAL é Data & AI Manager na EloGroup
DANIEL FRANZOLIN é Especialista de dados e modelagem na re.green











