Por Felipe Gochi, com colaboração de Fabio Catein e Rodrigo Bassani
- O Apache NiFi é uma ferramenta de processamento e orquestração de dados de código aberto, projetada para facilitar o movimento das informações entre diferentes sistemas em tempo real.
- Por ser altamente escalável e tolerante a falhas, ele se torna adequado para lidar com grandes volumes de dados em ambientes distribuídos.
- Essas características fazem do Apache NiFi um poderoso habilitador da perspectiva da tecnologia e do negócio, destravando valor importante para as organizações.
Dentro de um contexto em que as organizações têm a demanda de ser cada vez mais inteligentes na captura e tratamento de seus dados, para cultivar uma cultura data-driven, o Apache NiFi se apresenta como uma solução robusta e flexível. Essa ferramenta tem o potencial de melhorar a forma como as organizações coletam e processam dados, além de garantir uma maior segurança dos mesmos. Neste artigo, vamos explorar no detalhe o funcionamento dessa ferramenta, e como ela é capaz de gerar valor para o negócio.
O que é Apache NiFi?
O Apache NiFi é uma ferramenta de processamento e orquestração de dados de código aberto, projetada para facilitar o movimento das informações entre diferentes sistemas em tempo real. Ele fornece uma interface gráfica intuitiva para criar, gerenciar e monitorar esses fluxos. O Apache NiFi é altamente escalável e tolerante a falhas, o que o torna adequado para lidar com grandes volumes de dados em ambientes distribuídos. Ele permite que os usuários criem fluxos chamados de “data flows” mediante a simples e intuitiva ação de arrastar e soltar componentes pré-construídos, chamados de “processors”, na sua interface gráfica.
Como funciona a arquitetura do Apache NiFi?
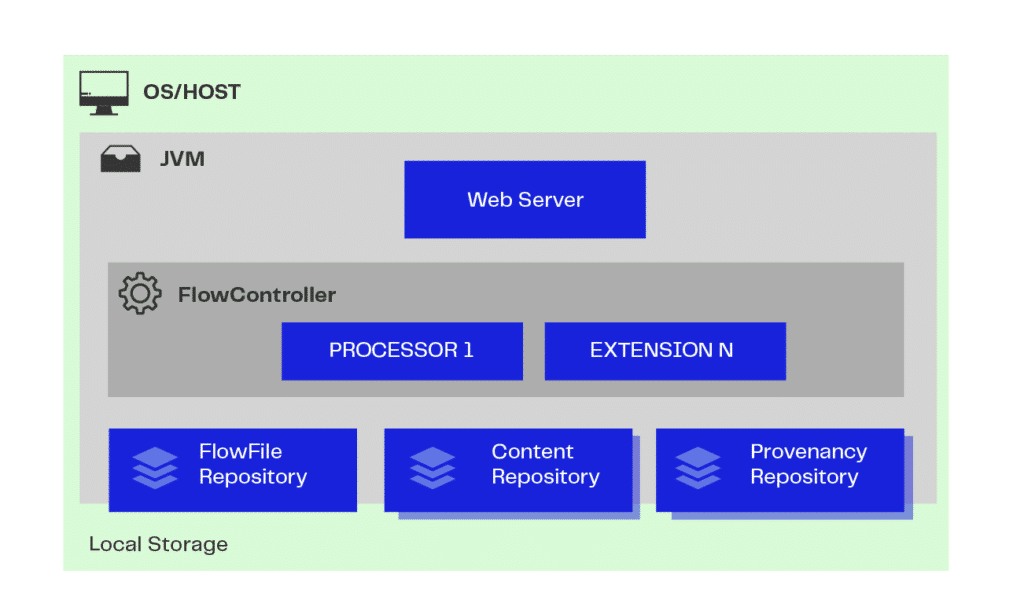
A arquitetura do Apache NiFi é executada em uma JVM (Java Virtual Machine, ou máquina virtual Java) hospedada no Sistema Operacional escolhido pelo usuário a partir de suas necessidades específicas.
- Web Server: é o repositório de APIs de comando e controle NiFi em HTTP;
- Flow Controller: a partir dessas APIs, fornece threads, ou processamentos paralelos, e gerencia o agendamento das extensões para que elas sejam executadas;
- Extension/Processor: são mecanismos e operações que podem ser executadas dentro da JVM, gerando arquivos de dados;
- FlowFile Repository: armazena e faz o acompanhamento das execuções e dos estados desses dados;
- Content Repository: é responsável por armazenar os conteúdos desses dados. Pode haver mais de um repositório de conteúdo, sendo o dado fracionado fisicamente para melhor proveito de espaço e armazenamento;
Os processors do NiFi oferecem uma ampla gama de funcionalidades, como transformação de dados, enriquecimento, filtragem, roteamento, integração com sistemas externos, entre outros. Esses processors podem ser configurados e conectados para criar fluxos complexos, permitindo a ingestão, processamento e entrega de dados em tempo real.
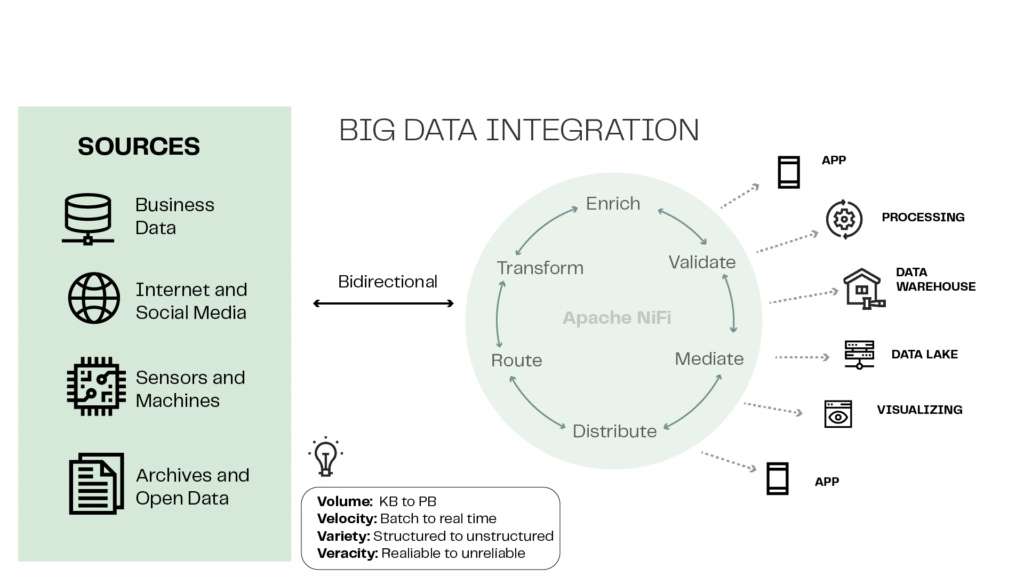
O Apache NiFi é amplamente utilizado em diversas áreas, como análise de dados em tempo real, Internet das Coisas (IoT), processamento de dados de logs, integração de sistemas e migração de dados. Sua flexibilidade, escalabilidade e recursos avançados o tornam uma ferramenta poderosa para lidar com o fluxo de dados em ambientes complexos e em constante evolução. Além disso, como é um projeto de código aberto da Apache Software Foundation, o NiFi possui uma comunidade ativa de desenvolvedores que contribuem com melhorias e recursos adicionais.
Gerando valor com Apache NiFi
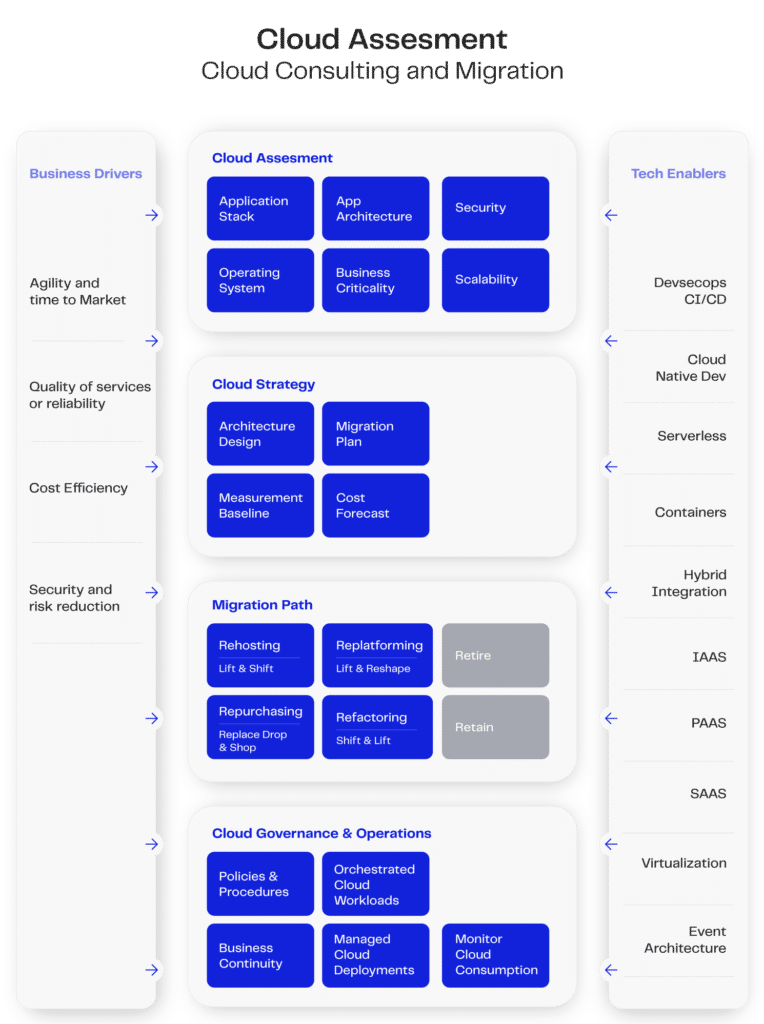
Dentro desse contexto, um tema de extrema relevância é o CAF (Cloud Adoption Framework, ou “Framework de adoção da nuvem” em português). Este é um guia completo para a adoção eficiente e segura da computação em nuvem, abordando aspectos técnicos, organizacionais e operacionais. Com foco em governança, habilidades necessárias, arquitetura, segurança, operações e otimização de custos, o CAF ajuda as empresas a alinharem seus objetivos a uma estratégia de desenvolvimento em cloud, promovendo a colaboração e impulsionando a inovação. As principais plataformas de nuvem oferecem serviços focados no CAF, como por exemplo o AWS Cloud Adoption Framework da AWS.
A imagem anterior demonstra como podemos alcançar esse objetivo, e a adoção do Apache NiFi, em conjunto com o Kubernetes (veja nosso insight sobre Kubernetes), auxilia na execução dos frames para o CAF em casos específicos (lembrando que a adoção dessas ferramentas deve contemplar as particularidades de cada projeto, como explicado em nosso artigo sobre Kubernetes).
Considerando as características do Apache Nifi, somos capazes de inferir diferentes capacidades que o tornam uma ferramenta habilitadora. Assim, encontramos diferentes categorias descritas na aba de Tech Enablers:
- Deploy feito com tecnologias de container e virtualização, como Docker e Kubernetes;
- Devsecops controlado pelo ambiente de deploy, sendo facilmente integrado a diferentes tipos de contexto;
- Com diferentes modos de configuração e módulos de utilização, o NiFi pode ser uma ferramenta crucial para integrações entre redes locais e remotas (hybrid integration);
- Enquadra-se como SAAS com diferentes tipos de operações.
- Possibilidade de uma arquitetura baseada em eventos (event architecture).
Como habilitadora tecnológica para diferentes propósitos, sua robustez aliada à sua flexibilidade possibilita também que os Business Drivers sejam acionados da melhor forma possível. Vamos explorar a seguir formas como o Apache NiFi pode se tornar um habilitador e gerar valor para o negócio.
Plataforma de ingestão de dados
O data ingestion, ou ingestão de dados, é um termo que se refere ao processo de coleta, importação e armazenamento de dados em um sistema ou plataforma para posterior processamento e análise. É a primeira etapa no fluxo, onde os dados brutos são capturados de várias fontes e preparados para uso posterior.
Consumindo de múltiplas fontes
Em um ambiente de alta volumetria, o processo de data ingestion precisa lidar com grandes volumes de dados e garantir que eles sejam capturados, processados e armazenados de maneira eficiente e escalável.
Existem alguns aspectos importantes a se considerar nesse processo:
- Diversidade de fontes: em um ambiente distribuído, os dados podem ser provenientes de várias fontes diferentes, como bancos de dados, sistemas legados, dispositivos IoT, serviços de nuvem, entre outros.
- Volume e velocidade: em um ambiente distribuído, os dados podem ser gerados em grandes volumes e em alta velocidade. Lidar com a ingestão de grandes quantidades de dados requer uma infraestrutura robusta e escalável para garantir que todos os dados sejam capturados e processados sem perda ou atrasos significativos.
- Escalabilidade: para lidar com alta volumetria, é necessário que o sistema de ingestão seja capaz de escalar, ou seja, adicionar recursos adicionais à medida que a demanda aumenta. Isso pode ser alcançado através de uma arquitetura distribuída, em que vários nós ou servidores trabalham em conjunto para processar os dados de forma paralela e escalável.
- Distribuição de carga: distribuir a carga de trabalho entre os diferentes nós do sistema é essencial para evitar gargalos e garantir um processamento eficiente. Isso pode ser feito por meio de técnicas como fracionamento de dados, roteamento inteligente e balanceamento de carga, para garantir que cada nó esteja sendo utilizado de forma equilibrada.
- Processamento em tempo real: em um ambiente de alta distribuição, é comum que os dados sejam gerados e transmitidos em tempo real. Portanto, a capacidade de ingestão deve ser projetada para lidar com a velocidade de fluxo dos dados, permitindo o processamento e armazenamento em tempo real, sem atrasos significativos. Isso envolve a implementação de sistemas de processamento de eventos em tempo real e a adoção de tecnologias que suportem baixa latência.
- Monitoramento e gerenciamento: em um ambiente de alta volumetria e distribuição, é essencial ter um monitoramento abrangente do processo de ingestão. Isso envolve o acompanhamento da taxa de ingestão, o desempenho dos nós de processamento, a detecção de gargalos e a capacidade de ajustar recursos conforme necessário. Além disso, é importante ter ferramentas e mecanismos de gerenciamento centralizados para facilitar a administração do sistema e a resolução de problemas.
Todos esses requisitos necessários para ingestão de dados em um ambiente de alta volumetria e diferentes fontes exigem um controle mais refinado dos custos de sustentação dessa arquitetura. Devemos, então, nos atentar a alguns aspectos importantes para redução de custos e otimização de performance, tais como:
- Uso de recursos compartilhados: uma das principais vantagens da computação distribuída é a capacidade de compartilhar recursos entre diferentes cargas de trabalho. Em vez de contar com servidores dedicados para cada aplicação, é possível utilizar uma infraestrutura compartilhada, como um cluster de servidores, onde diferentes tarefas e processos podem ser executados. Isso permite uma melhor utilização dos recursos disponíveis, reduzindo a necessidade de infraestrutura dedicada para cada aplicação.
- Elasticidade e escalabilidade sob demanda: uma arquitetura distribuída bem projetada permite dimensionar os recursos de acordo com a demanda. Com a elasticidade e a escalabilidade sob demanda, é possível adicionar ou remover recursos conforme necessário. Isso permite ajustar a capacidade de processamento de acordo com as necessidades reais, evitando custos excessivos com recursos ociosos.
- Uso de algoritmos otimizados: o uso de algoritmos otimizados para computação distribuída pode reduzir o tempo de processamento e, consequentemente, os custos associados. Algoritmos eficientes podem minimizar a quantidade de dados transferidos entre os nós, otimizar o uso da memória e reduzir o consumo de recursos computacionais. Isso resulta em um processamento mais rápido e eficiente, o que pode reduzir os custos operacionais.
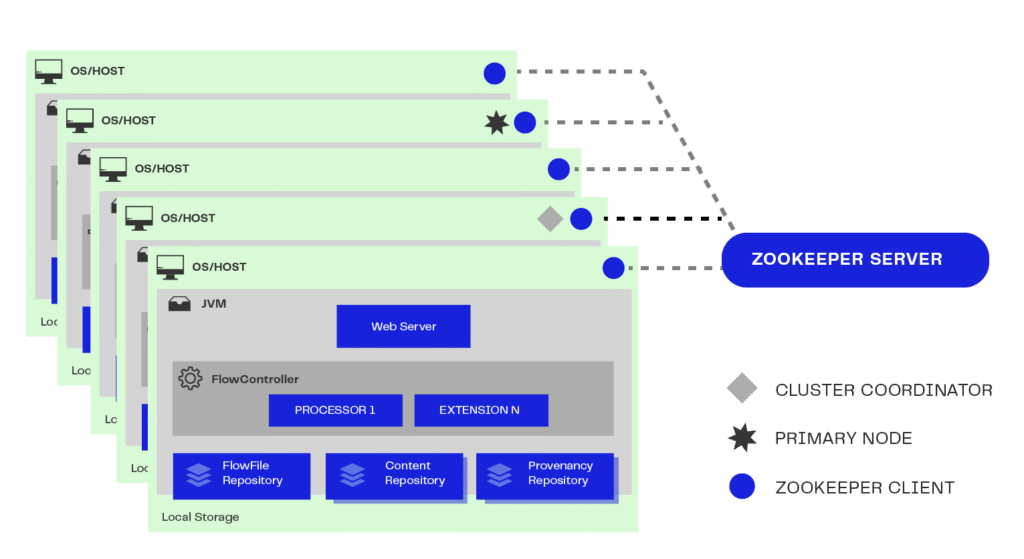
Além dos recursos de computação associados a soluções distribuídas, ainda temos mais um aspecto importante: o espaço de armazenamento em disco. Para isso há duas ações que podem ser tomadas para melhorar o volume do armazenamento e otimizar os processamentos de dados:
- Compressão de Dados: a compressão de dados é um processo de redução do tamanho de arquivos ou dados, a fim de ocupar menos espaço de armazenamento ou ser transmitido mais eficientemente em redes de comunicação. O objetivo da compressão de dados é reduzir o número de bits necessários para representar as informações sem perder dados essenciais.
- Formato de arquivo: a escolha do formato de arquivo adequado pode ter um impacto significativo no desempenho e na eficiência do processamento de dados em um ambiente de big data. Formatos como Parquet, Avro e ORC são comumente usados, pois são otimizados para compressão, leitura eficiente e suporte a esquemas.
Integrações e acessos democratizados
Com uma diversidade de projetos e demandas de dados surgindo dentro do ambiente coorporativo, um sistema que possibilite diferentes times trabalharem de forma simultânea e com controle total de seus processos é essencial para o crescimento orgânico de uma empresa data-driven. E quanto mais aculturados forem seus times, melhor serão os resultados, o que pode ser feito via treinamentos específicos, workshops de aculturamento em tecnologias chave, entre outros.
O Apache NiFi pode ser incluído no ecossistema de softwares de diferentes maneiras. Por ser uma tecnologia open-source, é possível instalá-lo de diferentes formas, mas sua forma mais otimizada é via Kubernetes, podendo assim ser entregue em ambientes on-premises e em nuvens.
Para o acesso democrático desses ambientes, podemos usar serviços nativos da nuvem como parte das integrações. Um exemplo disso é a integração para autenticação do ambiente Apache NiFi com o serviço Amazon Cognito.
Amazon Cognito x Apache NiFi
O Amazon Cognito é um serviço de gerenciamento de identidade e acesso oferecido pela Amazon Web Services (AWS). Ele foi projetado para ajudar os desenvolvedores a adicionarem facilmente recursos de autenticação, autorização e gerenciamento de usuários em seus aplicativos da web e móveis, permitindo que eles concentrem seus esforços no desenvolvimento do aplicativo em si, em vez de se preocuparem com a complexidade da construção e manutenção de sistemas de autenticação.
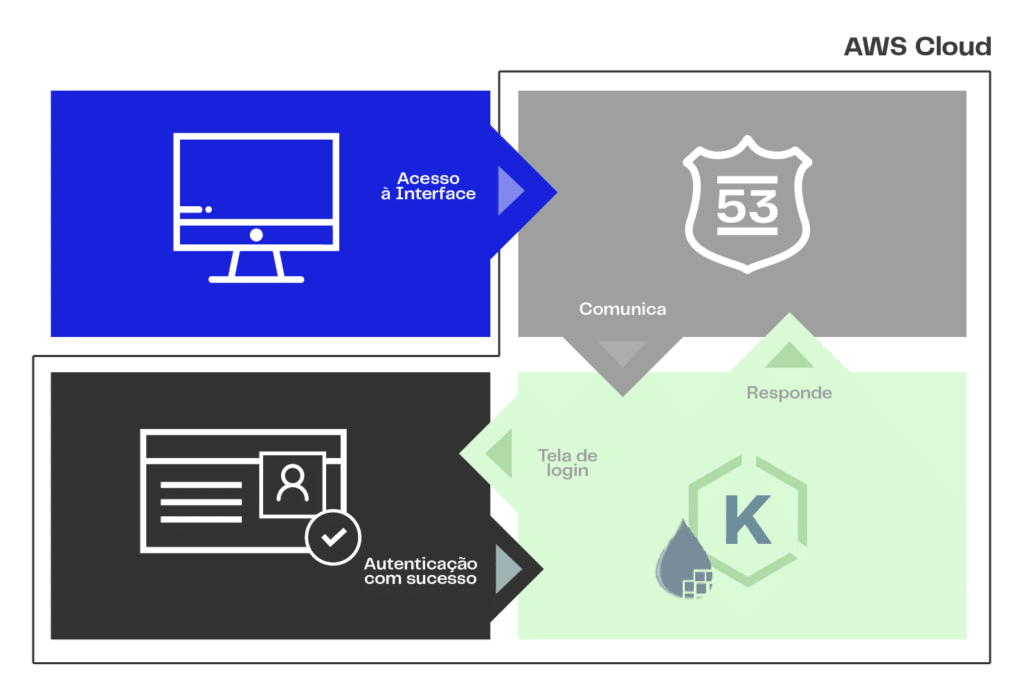
O fluxo demonstrado na imagem tem toda sua comunicação de autorização e autenticação baseada no protocolo OIDC. Ele demonstra como funciona o processo de autenticação para liberação de um usuário à interface do Apache NiFi via rede privada, passando pelo resolvedor de DNS Route 53. Ao acessar a interface do NiFi, caso o usuário não esteja autenticado, ele é direcionado para a tela de login do Amazon Cognito. Ao logar, a interface gráfica do NiFi trará diferentes possibilidades para ações de administração e uso do sistema (ACL).
Caso de uso
Em um caso de uso dentro de uma organização, consumimos 967 tabelas de dados totalizando 9.6 terabytes de informações críticas. O desafio é claro: como essa organização pode mover, transformar e gerenciar essa quantidade massiva de dados de maneira confiável e eficiente? Aqui entra o Apache NiFi, uma ferramenta de código aberto projetada para automatizar o fluxo de dados entre sistemas diversos.
No caso em questão, o Apache NiFi foi empregado como uma solução de ponta a ponta para atender às demandas complexas dessa organização. Vejamos como ele desempenhou um papel fundamental em enfrentar esse desafio:
- Coleta simplificada: o Apache NiFi permitiu que a organização coletasse dados de uma ampla variedade de fontes, desde bancos de dados tradicionais até feeds de dados em tempo real. Sua interface visual intuitiva tornou a configuração desses fluxos de coleta uma tarefa acessível mesmo para usuários menos técnicos.
- Transformação dinâmica: com a capacidade de aplicar transformações em tempo real aos dados, o NiFi facilitou a limpeza e a formatação dos dados de acordo com as necessidades da organização. Isso reduziu a carga sobre os sistemas de destino, garantindo que apenas os dados relevantes fossem transmitidos.
- Segurança em foco: considerando o valor sensível dos dados, a segurança era de extrema importância. O NiFi ofereceu recursos avançados de segurança, incluindo criptografia, autenticação e autorização granular, garantindo que os dados em trânsito permanecessem protegidos.
- Escalabilidade robusta: à medida que a organização crescia, o volume de dados também aumentava. O Apache NiFi lidou com isso elegantemente, permitindo a expansão horizontal dos recursos para acomodar maiores cargas de dados, sem comprometer o desempenho.
- Monitoramento em tempo real: a visibilidade é crucial em cenários de Big Data. O NiFi forneceu um painel de controle em tempo real, permitindo que os administradores monitorassem o fluxo de dados, identificassem gargalos e respondessem a problemas rapidamente.
O resultado foi impressionante: o Apache NiFi possibilitou que a organização não apenas superasse o desafio de lidar com 9.6 terabytes de dados distribuídos em 967 tabelas, mas também transformasse esse desafio em uma oportunidade para otimizar seus processos, reduzir custos e tomar decisões mais fundamentadas com base nos insights extraídos dos dados.
Em resumo, o Apache NiFi demonstrou sua eficácia em lidar com cenários complexos de Big Data, permitindo que essa organização enfrentasse os desafios de movimentação e gerenciamento de dados em larga escala com confiança e sucesso. Com sua flexibilidade, segurança e escalabilidade, o Apache NiFi se destaca como uma ferramenta valiosa para aqueles que buscam otimizar suas operações em um mundo movido a dados.
Conclusão: Apache NiFi como facilitador para a ingestão de dados
Podemos considerar o Apache NiFi um facilitador para a ingestão de dados nas organizações. Ele fornece uma série de recursos e funcionalidades que têm o potencial de tornar mais eficiente a maneira como as empresas lidam com a coleta, processamento e movimentação de informações. Ele ajuda a garantir segurança dos dados, permite controle de acesso granular, facilita a colaboração entre equipes, possibilita auditoria de atividades, isola ambientes, previne erros acidentais, empodera usuários com acesso relevante e se adapta à evolução do negócio, contribuindo para a eficiência e segurança no fluxo de dados empresariais.
Com direcionamento adequado, o NiFi agiliza a integração de dados, automatiza processos e permite análises em tempo real, impulsionando a eficiência operacional, tomada de decisões embasada em dados e adaptação ágil, fortalecendo o desempenho geral do negócio.
FELIPE GOCHI é especialista em engenharia de dados na EloGroup
FABIO CATEIN é especialista em engenharia de dados sênior na EloGroup
RODRIGO BASSANI é CTO na EloGroup











