By Felipe Gochi, in collaboration with Fabio Catein and Rodrigo Bassani
- Apache NiFi is an open-source data processing and orchestration tool designed to ease information’s movement between different systems in real time.
- Because it is highly scalable and fault-tolerant, it is well suited to dealing with large volumes of data in distributed environments.
- These characteristics make Apache NiFi a powerful enabler from a technology and business perspective, unlocking important value for organizations.
Within a context in which organizations are demanding increasingly intelligence in capturing and processing data, in order to cultivate a data-driven culture, Apache NiFi presents itself as a robust and flexible solution. This tool has the potential to improve the way organizations handles data, as well as guaranteeing greater security to it. In this article, we will explore in detail how this tool works and how it can generate value for the business.
What is Apache NiFi?
Apache NiFi is an open-source data processing and orchestration tool designed to help the movement of information between different systems in real time. It provides an intuitive graphical interface for creating, managing and monitoring these flows. Apache NiFi is highly scalable and fault-tolerant, which makes it suitable for handling large volumes of data in distributed environments. It allows users to create the so-called “data flows” by simply and intuitively dragging and dropping pre-built components, “processors”, onto its graphical interface.
How does the Apache NiFi architecture work?
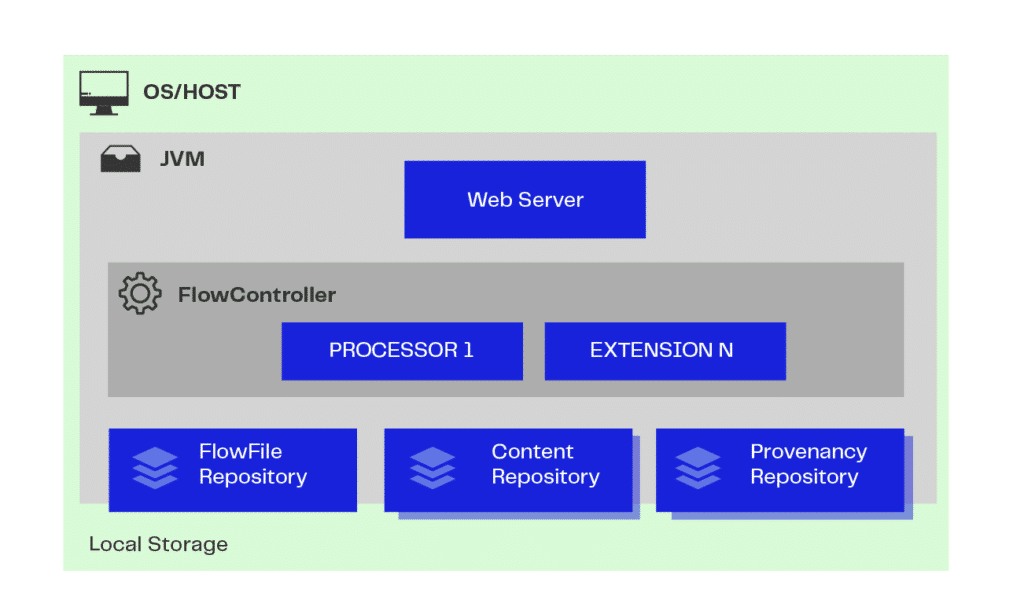
The Apache NiFi architecture runs on a JVM (Java Virtual Machine) hosted on the Operating System chosen by the user based on their specific needs.
- Web Server: is the repository of NiFi command and control APIs in HTTP;
- Flow Controller: from these APIs, it provides threads or parallel processing and manages the scheduling of extensions so that they are executed;
- Extension/Processor: these are mechanisms and operations that can be executed within the JVM, generating data files;
- FlowFile Repository: stores and checks the execution and status of this data; and
- Content Repository: handles storing the contents of this data. There can be more than one repository, where data is physically fractionated to make better use of space and storage.
NiFi processors offer a wide range of functionalities, such as data transformation, enrichment, filtering, routing and integration with external systems, among others. These processors can be configured and connected to create complex flows, allowing data to be ingested, processed and delivered in real time.
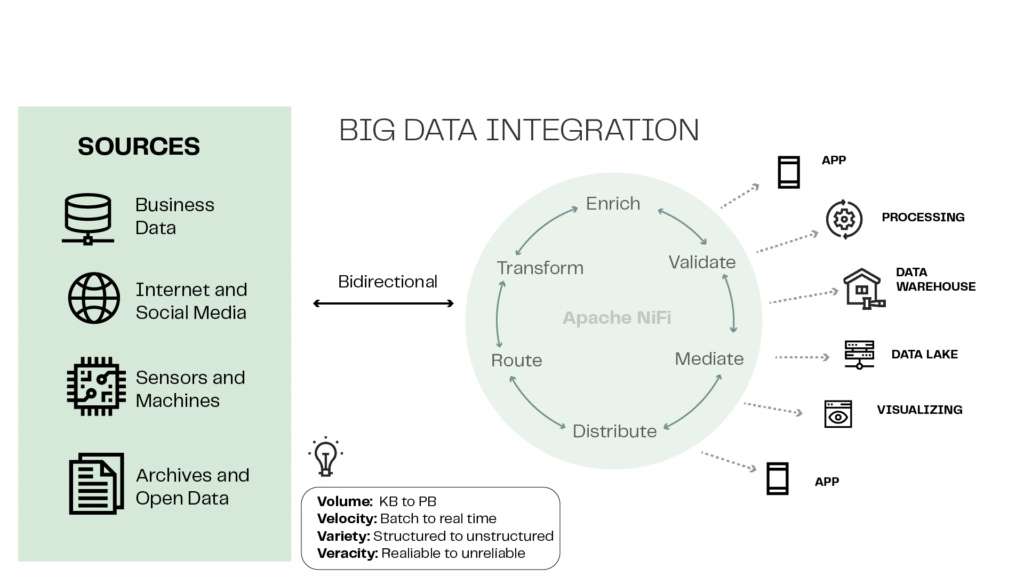
Apache NiFi is widely used in many areas, like in data analysis, Internet of Things (IoT), log data processing, systems integration and data migration. Its flexibility, scalability and advanced features make it a powerful tool for dealing with the flow of data in complex and constantly evolving environments. Also, since it is Apache Software Foundation’s open-source project, NiFi has an active community of developers who contribute with improvements and added features.
Generating value with Apache NiFi
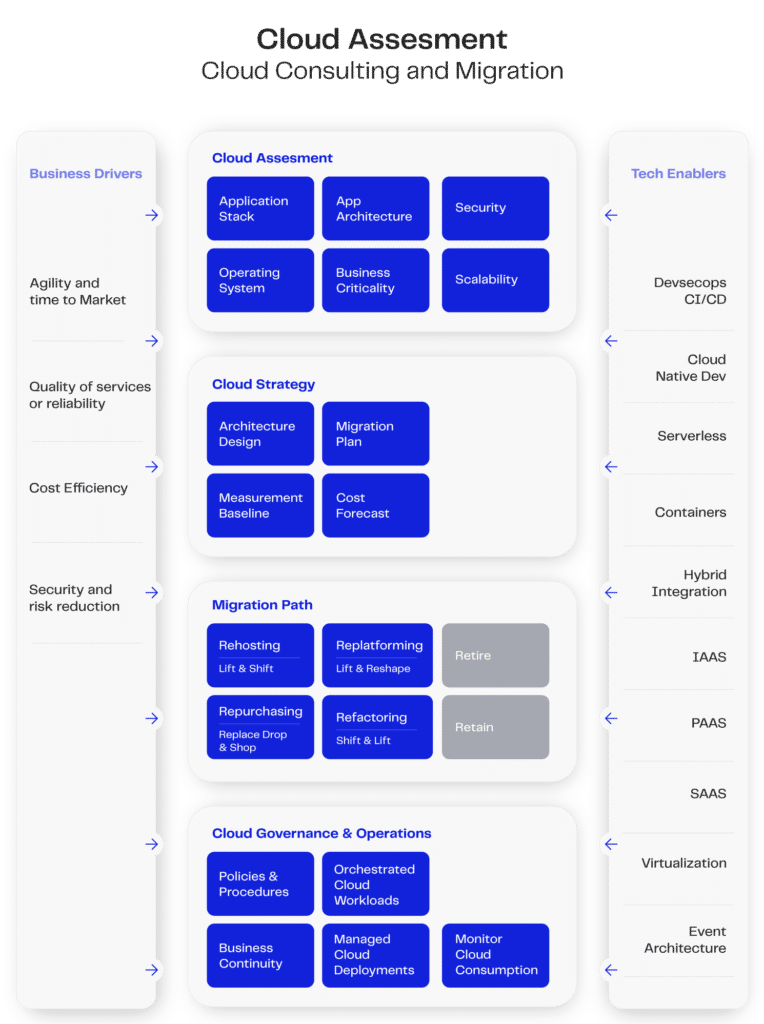
In this subject, an extremely important topic is the CAF (Cloud Adoption Framework). It is a complete guide to the efficient and secure adoption of cloud computing, covering technical, organizational and operational aspects. With a focus on governance, necessary skills, architecture, security, operations and cost optimization, the CAF helps companies align their goals with a strategy that promotes collaboration and innovation. The main cloud platforms offer services focused on CAF, such as the AWS Cloud Adoption Framework.
The image above shows how we can achieve this goal by adopting Apache NiFi in conjunction with Kubernetes to execute CAF frames in specific cases (remembering that the adoption of these tools must consider the particularities of each project, as explained in our article on Kubernetes).
Considering the characteristics of Apache NiFi, we can infer different capabilities that make it an enabling tool. Thus, we find different categories described in the Tech Enablers tab:
- Deployment using container and virtualization technologies, such as Docker and Kubernetes;
- Devsecops controlled by the deployment environment easily integrated into different types of context;
- With different configuration modes and utilization modules, NiFi can be a crucial tool for integrations between local and remote networks (hybrid integration);
- It can be used as a SAAS with different types of operations; and
- Possibility of an event-based architecture.
As a technological enabler for different purposes, its robustness combined with its flexibility also allows Business Drivers to be activated in the best way. Let’s explore how Apache NiFi can become an enabler and generate value for the business.
Data ingestion platform
Data ingestion is a term that refers to the process of collecting, importing and storing data in a system or platform for later processing and analysis. It is the first stage in the flow, where raw information is captured from various sources and prepared for later use.
Consuming from multiple sources
In a high-volume environment, the data ingestion process needs to deal with large volumes of data and ensure that it is captured, processed and stored in an efficient and scalable manner.
There are some important aspects to consider in this process:
- Diversity of sources: in a distributed environment, data can come from many different sources, such as databases, legacy systems, IoT devices, cloud services, etc.;
- Volume and speed: in a distributed environment, data can be generated in large volumes and at high speed. Dealing with the ingestion of substantial amounts of data requires a robust and scalable infrastructure to ensure that all data is captured and processed without loss or significant delays;
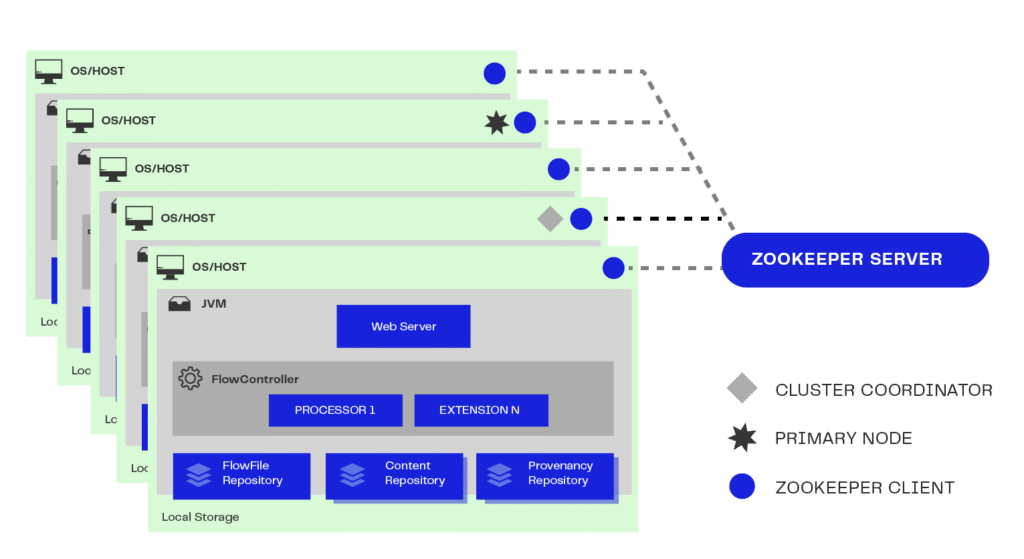
- Scalability: to deal with high volumetrics, the ingestion system needs to be able to scale, which means add more resources as demand increases. This can be achieved through a distributed architecture, where several nodes or servers work together to process the data in a parallelized and scalable way;
- Load distribution: distributing the workload between the different nodes in the system is essential to avoid bottlenecks and guarantee efficient processing. This can be done using techniques like data fractionation, intelligent routing and load balancing to ensure that each node is being utilized in a balanced way;
- Real-time processing: in a high-distribution environment, it is common for data to be generated and transmitted in real time. Therefore, ingestion ability must be designed to cope with the speed of data flow, allowing for real-time processing and storage without significant delays. This involves implementing real-time event processing systems and adopting technologies that support low latency; and
- Monitoring and management: in a high volume and distribution environment, it is essential to have comprehensive monitoring of the ingestion process. This involves tracking the ingestion rate, the performance of the processing nodes, detecting bottlenecks and being able to adjust resources as necessary. In addition, it is important to have centralized management tools and mechanisms to ease system administration and troubleshooting.
All these requirements for data ingestion in a high-volume environment with various sources demand a more refined control of the costs of supporting this architecture. We must, therefore, pay attention to some important aspects to reduce costs and optimize performance, such as:
- Use of shared resources: one of the main advantages of distributed computing is the ability to share resources between different workloads. Instead of having dedicated servers for each application, it is possible to use a shared infrastructure, like a cluster of servers, where different tasks and processes can be carried out. This allows for better utilization of available resources, reducing the need for dedicated infrastructure for each application;
- Elasticity and scalability on demand: a well-designed distributed architecture allows resources to be scaled according to demand. With elasticity and scalability on demand, resources can be added or removed as needed. This makes it possible to adjust processing ability according to real needs, avoiding excessive costs with idle resources; and
- Use of optimized algorithms: the use of optimized algorithms for distributed computing can reduce processing time and, consequently, the associated costs. Efficient algorithms can minimize the amount of data transferred between nodes, optimize the use of memory and reduce the consumption of computing resources. This results in faster and more efficient processing, which can reduce operating costs.
In addition to the computing resources associated with distributed solutions, there is another important aspect: disc storage space. There are two actions that can be taken to improve storage volume and optimize data processing:
- Data Compression: data compression is a process of reducing the size of files or data, causing it to occupy less storage space or to be transmitted more efficiently over communication networks. It reduces the number of bits needed to stand for information without losing essential data; and
- File format: choosing the right file format can have a significant impact on the performance and efficiency of data processing in a big data environment. Formats like Parquet, Avro and ORC are commonly used, as they are optimized for compression, efficient reading and schema support.
Democratized integrations and access
With a diversity of projects and data demands arising within the corporate environment, a system that enables different teams to work simultaneously and with total control of their processes is essential for the organic growth of a data-driven company. The more acculturated your teams are, the better the results will be, which can be done through specific training, workshops on key technologies, etc.
As it is an open-source technology, Apache NiFi can be included in the software ecosystem in different ways, but its most optimized form is via Kubernetes, so it can be delivered in on-premises and cloud environments.
For democratic access to these environments, we can use native cloud services as part of the integrations. An example of this is the integration for authenticating the Apache NiFi environment with the Amazon Cognito service.
Amazon Cognito x Apache NiFi
Amazon Cognito is an identity and access management service offered by Amazon Web Services (AWS). It is designed to help developers easily add authentication, authorization and user management features to their web and mobile applications, allowing them to focus their efforts on developing the application itself, rather than worrying about the complexity of building and maintaining authentication systems.

The flow shown in the image has all its authorization and authentication communication based on the OIDC protocol. It shows how the authentication process works to release a user to the Apache NiFi interface via a private network, passing through the Route 53 DNS resolver. When accessing the NiFi interface, if the user is not authenticated, they are directed to the Amazon Cognito login screen. By logging in, the NiFi graphical interface will bring up different possibilities for system administration and use (ACL) actions.
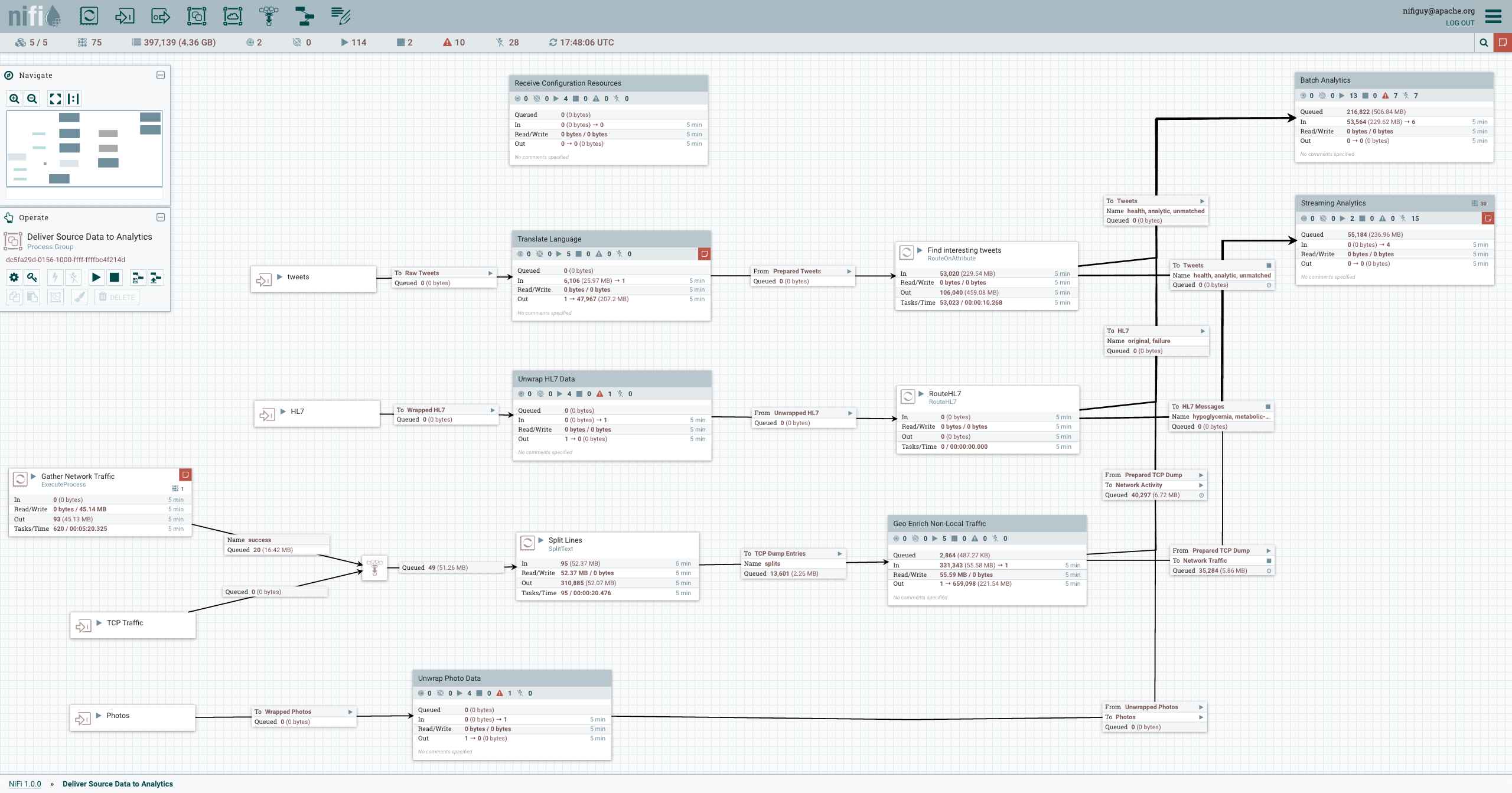
Use case
In one use case within an organization, we consume 967 data tables totaling 9.6 terabytes of critical information. The challenge is clear: how can this organization move, transform and manage this massive amount of data reliably and efficiently? This is where Apache NiFi comes in, an open-source tool designed to automate the flow of data between different systems.
Apache NiFi was deployed as an end-to-end solution to meet the complex demands of this organization. Let’s see how it played a key role in meeting this challenge:
- Simplified collection: Apache NiFi enabled the organization to collect data from a wide variety of sources, from traditional databases to real-time data feeds. Its intuitive visual interface made setting up these collection flows an accessible task even for less technical users.
- Dynamic transformation: with the ability to apply real-time transformations to data, NiFi has made it easier to clean and format data according to the organization’s needs. This reduced the load on the target systems, ensuring that only the relevant data was transmitted.
- Security in focus: considering the sensitive value of the data, security was of the utmost importance. NiFi offered advanced security features, including encryption, authentication and granular authorization, ensuring that data in transit remained protected.
- Robust scalability: as the organization grew, so did the volume of data. Apache NiFi handled this elegantly, allowing resources to be expanded horizontally to accommodate larger data loads, without compromising performance.
- Real-time monitoring: visibility is crucial in Big Data scenarios. NiFi provided a real-time dashboard, allowing administrators to check the flow of data, identify bottlenecks and respond to problems quickly.
The result was impressive: Apache NiFi enabled the organization not only to overcome the challenge of dealing with 9.6 terabytes of data distributed across 967 tables, but also to turn this challenge into an opportunity to optimize its processes, reduce costs and make more informed decisions based on the insights extracted from the data.
In short, Apache NiFi showed its effectiveness in dealing with complex Big Data scenarios, enabling this organization to face the challenges of moving and managing large-scale data with confidence and success. With its flexibility, security and scalability, Apache NiFi stands out as a valuable tool for those looking to optimize their operations in a data-driven world.
Conclusion: Apache NiFi as a facilitator for data ingestion
We can consider Apache NiFi a facilitator for data ingestion in organizations. It provides a series of features and functionalities that have the potential to make the way companies deal with collecting, processing and moving information more efficient. It helps guarantee data security, allows granular access control, eases collaboration between teams, enables auditing of activities, isolates environments, prevents accidental errors, empowers users with relevant access and adapts to the evolution of the business, contributing to efficiency and security in the flow of business data.
With the right direction, NiFi speeds up data integration, automates processes and enables real-time analyses, boosting operational efficiency, data-based decision-making and agile adaptation, strengthening overall business performance.
FELIPE GOCHI works as Data Engineering Specialist at EloGroup.
FABIO CATEIN works as Senior Data Engineering Specialist at EloGroup.
RODRIGO BASSANI works as CTO at EloGroup.











