By EloInsights
- Companies that want to unlock their potential for continuous transformation (driven by change) need to cultivate foundational digital competences.
- Among the capabilities that need to be refined and optimized is the process of deploying digital product features and updates.
- This competence, although part of a bigger picture, is key to contributing to the process of making the organization more agile and adaptable to a world of constant disruption.
Within the context of an organization’s digital transformation that enables the strategic use of enabling technologies as business levers, one of the key aspects is to establish a culture of continuous transformation. To do this, companies must create foundations that enable this change-orientated culture, digital competences that will provide the support needed for this entire process.
In this article, we will look at an essential aspect of a company’s IT work. It relates to the digital competences that need to be refined and optimized to guarantee the health and transformational capacity of an organization: the process of deploying digital product features and updates.
But what is deployment anyway?
It is a process in which development teams, having already carried out the necessary tests on a particular feature or aspect of a piece of software, continue to make it available in the development, QA (quality assurance) and production environments. In other words, the software moves on to environments where it has not yet been tested, and traditionally, this is when any faults and the need for corrections appear.
“No matter how many tests are carried out. When the time comes to make the application available, it is common for difficulties to arise until everything is running reliably for the user”, points out Rodrigo Bassani, CTO at EloGroup.
Because it is such a critical aspect of the software development and deployment process, the way in which deployment is carried out has a significant impact on an organizations’ ability to remain agile and respond quickly to its ongoing transformation needs.
Below, we are going to detail some of the ways in which software deployment is carried out, from the most traditional (and least agile) to those aligned with practices considered to be the most modern and efficient:
1 – Manual Deployment
It is an older type of deployment, often associated with great pain at the time of adoption and with an on-premises structure (with local servers).
It consists of sending the script with the software update, an instruction manual to be executed by a person with access to the servers, usually a third party who was not involved in the development of the software itself.
“In this scenario, the team of developers would call in and wait for this person to carry out the deployment”, explains Bassani. “After following the instructions, they would call back so that the team could check whether the process had been carried out properly or whether something had failed”.
One problem was one of scale, since scaling up this operation required more people to execute the script, which increased complexity.
The lack of alignment and asymmetry of knowledge between the development teams and the person executing the script tended, in this model, to translate into long deployments that often did not go completely satisfactorily, regardless of the sending of an instruction manual.
“In the case of more critical deployments in this model, it was not uncommon to see redundancies during the process”, remembers Bassani.
2 – Partially automated deployment
At a second stage, deployment becomes partially automated and aspects of its architecture begin to be considered.
The script is no longer run manually by a third party; code versioning of the software is already being worked on in a more structured way, in repositories that can be accessed by the developers themselves, and no longer by a person who has not took part in the creation of that program. There is a whole environment where commits (updates) to the code are submitted, registered and validated.
“Here, the deployment process begins to be optimized and becomes less painful for the teams”, says Bassani. The information can be made available both on-premises (data centers within the companies) and in the cloud providers, in a context where the code no longer needs to be on the developer’s machine.
This type of deployment reduces the number of human errors because it no longer involves a third party who has not followed the development process. The construction of the code is now managed by those who really know it and will provide support after the code is made available, which guarantees better visibility of the status of each deployment.
One of the advantages of this dynamic it is possible to roll back to the earlier version in case of a failure.
3 – Fully automated deployment (CI/CD – Continuous Integration and Continuous Deployment)
In this context, developers have complete control of the code, with tools that help build generation, versioning and making the software available in production. There is a considerable gain in efficiency, productivity and security in the process.
The greater control and maturity in the deployment process takes on a DevOps vision that involves a continuous cycle of integration and deployment (Continuous Integration and Continuous Deployment).
“Fridays are now quiet; it is no longer necessary to spend an entire weekend doing deployment. In the past, we used to have ‘go-lives’ of 36 hours uninterrupted in the office; we would nap, eat in there until the process was finished”, indicates Bassani.
The table below shows some of the possible deployment strategies, their respective advantages and disadvantages:
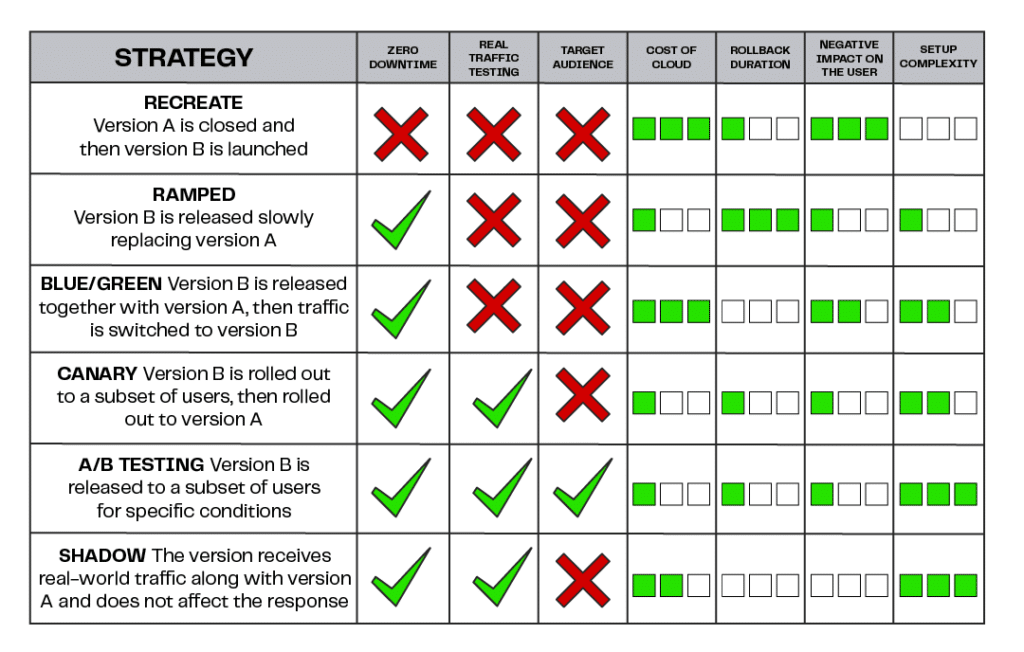
One of the most common strategies is A/B testing, in which a version of the software is made available to a specific set of users and its behavior is checked by the development team. In it, the duration of the roll-back if a failure is defined, as well as the impact on the user and the complexity of setting up the environment.
In an example of a deployment carried out in several locations, one possibility would be to make it available for a first location, observe its behavior in terms of user experience, and only then continue to deployment in the other locations, in case of success. “Today, with the cloud, this strategy is easy; the impact is very small within operations that are structured in their deployment process”, explains Bassani.

One of the elements that has a direct impact on how a deployment is carried out is the architecture of the application in question. In this respect, we can talk about the three main generations of architecture that have predominated in the market and how deploys were carried out within each of these contexts:
Client server
- Single deployment;
- Scale with vertical hardware;
- Model-view-controller (MVC) architecture;
- Single database; and
- More complex releases.
Around the year 2000, with the modernization of applications, the so-called “client server architecture” predominated. In this scenario, deployment required the installation of an executable file on the machine where it was to be carried out.
The only server was the database server and the applications ran completely on the workstations. Therefore, if an organization had 50 machines, for example, the developers had to generate a single deployment package and update each of the computers.
Without an exclusive server for the application, it was impossible to scale the deployment process in any other way. This increased the complexity of the process, which also became more costly and time-consuming.
N layers
- Independent deployment;
- Scale with horizontal hardware;
- Architecture with “N” layers;
- Single database; and
- Controlled release.
As technologies matured and infrastructure resources became more accessible, the so-called “N” Layers architecture became predominant, where applications could be divided into different logical and physical layers. In other words, this model already accommodated the existence of an application server, connected both to the database and to a lighter client, which only carried the application screen on the workstations.
This translated into an important advantage: although the application was still updated in its entirety in this paradigm, deployment no longer had to be carried out on all the machines that ran it locally, but on the “n” servers that served the total number of workstations.
If a single server served 50 machines, for example, it was necessary to update the application only on that layer, and no longer on all 50 computers. In this scenario, deployments became more controlled, cheaper and less time-consuming.
Microservice / Micro Frontend
- Deployment in parts;
- Scale by functional context;
- Distributed architecture;
- Multiple databases; and
- Autonomous and scalable releases.
The emergence of cloud computing service providers and their popularization marked a turning point in application architecture and represents a milestone in this regard.
The cloud, which already existed in private format, became more accessible in its public version, in a context where companies could now get a “piece” of a cloud data center, minimizing costs and increasing flexibility. This new paradigm opened the door to one of the most discussed formats at the moment: microservices-based architecture.
In this logic, applications leave their “monolith” format and start to be “broken down” into smaller pieces, different functional contexts that start to run in different, deployment-independent packages, which allows for more focused and precise updates that do not affect the whole application.
In the case of ERP (Enterprise Resource Planning) software, for example, the different modules, such as financial, customer registration or sales, now represent a separate and independent deployment package and microservice.
When deploys are carried out, they occur in the respective microservices, according to each change, which translates into a series of advantages. For example, while an update takes place in a particular microservice, the others are still unchanged and operational, which means no downtime for users.
An architecture based on microservices also enables an evolution in source code control tools and the automation of deploys and releases.
The differences in the administration and configuration of on premise and cloud setups
Below, are some of the main differences between the administration and configuration of on-premises setups (which run on local servers, operated by the organization itself) and cloud setups (servers run outside the organization, by on-demand infrastructure providers):
Characteristics of the administration and configuration of an on-premises setup:
- Software license management is required;
- Infrastructure capacity planning management;
- Physical management of servers and datacenters;
- Complex infrastructure provisioning;
- In-house deployment;
- Complexity in scaling applications;
- In-house OS patching; and
- More complex disaster recovery deployment process.
Within the on-premises environment, one of the main differences is the need for the organization itself to take responsibility for managing the types of software deployment and for the governance of the operating system supported in that environment.
Deployment takes place “in-house”, so IT teams need to provision infrastructure and have the physical location for it (“capacity planning”). This translates into greater complexity when it comes to scaling, in other words, increasing the size of this infrastructure, which happens through investments in hardware, rather than flexibly as in a cloud environment.
Applying patches and updates is also the responsibility of the organization.
The “disaster recovery” planning process, in which a contingency plan is determined if serious data center disruptions, such as in case of a successful cyber-attack, is more complex, as it often involves IT teams physically travelling to other locations to set up backup environments.
In short, on-premises configuration tends to be more costly. Until today it still represents the reality for many companies, to the extent that cloud setups are now starting to gain scale.
Features of the administration and configuration of a cloud setup:
- Flexibility to scale infrastructure;
- Efficiency in making new products available;
- “Pay as you go”;
- Optimization of deployment processes;
- Easier management;
- High availability; and
- Agility in setting up the disaster recovery process.
On the other hand, in a cloud environment, the organization can have more flexibility to scale its infrastructure as its needs increase, without having to invest in hardware. In this scenario, there is also no need to have and manage a physical space to house data centers.
This flexibility translates into greater efficiency in making new products available as well as in improving infrastructure management. In the “pay as you go” logic, if the organization needs to host a small application that takes up a small amount of server space, it can only hire the corresponding computing capacity.
In disaster recovery planning, the cloud environment is more configurable and makes it possible to make servers available without the need for physical presence in separate locations.
People first
When comparing the two types of environments, the conclusion is that on-premises is more complex, requires more steps to be taken and a greater number of employees or people responsible for the infrastructure. When you choose a cloud provider, this set of teams and services is already encapsulated in the contract.
But it is worth remembering that any deployment will never be just a click of a button. This is a process that requires levels of digital maturity and can be archaic and done amateurishly, whether in an on-premises or cloud environment.
Ultimately, what will make the difference is the team involved in this operation; the people and their ability to give the organization greater maturity in its digital competences.











